故障转移Failover
基于日志坐标的故障转移(Failover with Log Coordinates)
- 在二进制日志中,找到应用到每个从库的最新事件。
- 选择一个数据最新的从库作为新主库。
- 在新主库上确定日志坐标,使其与每个从库上最新应用的事件匹配。
- 在每个从库上执行正确的
CHANGE MASTER TO...语句。
执行基于日志坐标的故障转移时的潜在问题(Potential Problems When Executing a Failover with Log Coordinates)
执行故障转移时,若从库并非都为最新状态,复制拓扑可能出现不一致的风险:
- 若新主库落后于某个从库(即该从库已应用新主库日志末尾的事件 ),则该从库会重复应用那些事件。
- 若新主库领先于某个从库(即新主库的二进制日志包含该从库尚未应用的事件 ),则该从库会跳过那些事件。
执行基于日志坐标的故障转移时规避问题的方法(Avoiding Problems When Executing a Failover with Log Coordinates)
-
让 SQL 线程应用中继日志(relay log)中的所有事件。
-
选择一个数据最新的从库作为新主库。
-
在新主库上找到与每个从库最新事件匹配的日志坐标。
-
若部分从库比其他从库落后更多,在
CHANGE MASTER TO...语句中为不同从库提供的日志坐标会各不相同。
- 不能简单地在新主库上执行
SHOW MASTER STATUS来获取(通用的坐标 )。 - 相反,必须检查二进制日志以找到正确的坐标。
- 不能简单地在新主库上执行
-
在有多个主库接收客户端更新的环形拓扑中,找到数据最新的从库并确定正确的日志坐标会非常困难。
- 考虑使用全局事务标识符(GTIDs)。
在有多个主库接收客户端更新的环形拓扑中,找到数据最新的从库并确定正确的日志坐标会非常困难,因为每个从库应用操作的顺序与其他从库不同。为避免这种困难,可使用全局事务标识符(GTIDs)。
使用 GTID 的故障转移(Failover with GTIDs)
当使用 GTID 时,环形拓扑中的故障转移会变得简单:
- 在故障主库的从库上,通过执行一条
CHANGE MASTER TO语句即可绕过故障主库。 - 拓扑中的每个服务器会根据事务的 GTID 是否已见过,来决定忽略或应用从其他服务器复制来的事务。
非环形拓扑中的故障转移也同样简单:
- 临时将新主库配置为一个数据最新的从库的从库,直到新主库追上(数据进度 )。
- 在故障主库的从库上,执行
CHANGE MASTER TO语句,从新主库复制数据。
尽管 GTID 可防止源自单个服务器的事件重复,但无法防止源自不同服务器的冲突操作。故障转移后将应用程序重新连接到服务器时,必须小心,避免引入此类冲突。
复制线程Replication threads
复制线程(Replication Threads)
当从库连接到主库时:
- 主库会创建一个 Binlog dump 线程
- 从二进制日志中读取事件,并将其发送给从库的 I/O 线程。
- 从库默认会创建两个线程:
- 从库 I/O 线程
- 从主库的 Binlog dump 线程读取事件,并将其写入从库的中继日志(relay log)。
- 从库 SQL(或 “应用” )线程
- 在单线程从库上,应用中继日志中的事件;
- 在多线程从库上,将中继日志事件分配给工作线程(worker threads)
- 从库 I/O 线程
单线程从库(Single-Threaded Slaves)
- 从库默认是单线程的。
- 每个从库使用单个 SQL 线程来处理中继日志。
- 优点是,当通过单线程复制时,单个数据库内的数据可保证一致。
- 单线程从库可能导致从库延迟(即从库落后于主库 ):
- 若主库有多个客户端连接,可并行应用变更,但主库会在其二进制日志中序列化所有事件(按顺序记录 )。
- 从库在单个线程中按顺序执行这些事件,在高负载环境或从库硬件性能不足时,这可能成为瓶颈。
多线程从库(Multithreaded Slaves)
-
使用多线程从库来减少从库延迟。
-
将
slave_parallel_workers变量设置为大于 0 的值,以创建对应数量的工作线程。- 当有多个工作线程时,从库的 SQL 线程不直接应用事件,而是将任务委托给工作线程。
-
设置
slave_parallel_type变量以指定并行化策略。-
DATABASE(默认):更新不同数据库的事务会并行应用。
-
LOGICAL_CLOCK
:属于主库上同一二进制日志组提交的事务,会在从库上并行应用。
- 主库可通过
binlog_transaction_dependency_tracking变量配置二进制日志,以记录提交时间戳或写集合。 - 将
slave_preserve_commit_order变量设置为ON以保留提交顺序。
- 主库可通过
-
补充说明:
- “DATABASE” 策略仅在数据被分区到多个数据库、且主库上这些数据库被独立且并发更新时适用。必须不存在跨数据库约束,否则从库上可能违反这些约束。
- “LOGICAL_CLOCK” 策略使用提交时间戳或写集合来确定哪些事务可并行应用。依赖信息由主库生成。与提交时间戳相比,写集合可提供更高级别的并行性。启用
slave_preserve_commit_order后,执行线程会在提交前等待所有之前的事务提交。在此模式下,多线程从库永远不会进入主库未曾处于的状态。
控制从库线程(Controlling Slave Threads)
-
启动或停止从库上的 I/O 线程和 SQL 线程:
1 2START SLAVE; STOP SLAVE; -
单独控制线程:
1 2START SLAVE IO_THREAD; STOP SLAVE SQL_THREAD;- 在多线程从库中,无法单独控制 SQL 工作线程,因为这些线程由 SQL 线程管理。
-
启动线程直到满足指定条件:
1 2START SLAVE UNTIL SQL_AFTER_MTS_GAPS; START SLAVE SQL_THREAD UNTIL SQL_BEFORE_GTIDS = '0ed18583-47fd-11e2-92f3-0019b94b7e7:338'; -
断开从库与主库的连接:
1RESET SLAVE [ALL]
重置从库(Resetting the Slave)
通过执行 RESET SLAVE 命令,断开从库与主库的连接,以实现干净的重启:
- 清空
master.info和relay.log存储库 - 删除所有中继日志(relay logs)
- 启动一个新的中继日志文件
- 将
CHANGE MASTER TO语句中指定的任何MASTER_DELAY重置为 0 - 保留连接参数,因此无需执行
CHANGE MASTER TO即可重启从库- 执行
RESET SLAVE ALL以重置连接参数
- 执行
- 不会更改
gtid_executed、gtid_purged的值,也不会更改mysql.gtid_executed表
监控复制Monitoring replication
监控复制(Monitoring Replication)
|
|
有关 SHOW SLAVE STATUS 语句返回的所有字段的描述,请参见 https://dev.mysql.com/doc/refman/en/show-slave-status.html。
从库线程状态(Slave Thread Status)
Slave_IO_Running和Slave_SQL_Running列分别显示从库 I/O 线程和 SQL 线程的状态。- 每列的可能取值如下:
Yes:线程当前正在运行。No:线程未在运行。Connecting:线程正在运行,但尚未连接到主库。
主库日志坐标(Master Log Coordinates)
Master_Log_File 和 Read_Master_Log_Pos 列标识了 I/O 线程已传输的主库二进制日志中最新事件的坐标。
- 将主库日志坐标与在主库上执行
SHOW MASTER STATUS时显示的坐标进行比较。 - 如果
Master_Log_File和Read_Master_Log_Pos的值远落后于主库上的值,则表明主库和从库之间的事件网络传输存在延迟。
中继日志坐标(Relay Log Coordinates)
-
Relay_Log_File和Relay_Log_Pos列标识了 SQL 线程已执行的从库中继日志中最新事件的坐标。 -
Relay_Master_Log_File和Exec_Master_Log_Pos列对应主库二进制日志中的坐标。-
如果这些列的输出远落后于代表 I/O 线程坐标的
Master_Log_File和Read_Master_Log_Pos列:- 说明是 SQL 线程存在延迟,而非 I/O 线程
- 日志事件复制速度快于执行速度
-
-
Relay_Log_Space列指定所有中继日志文件的总组合大小。 -
Seconds_Behind_Master列存储最新中继日志事件与当前服务器时间的秒数差,用于识别从库延迟。 -
SQL_Delay指定从库必须落后于主库的秒数,该值在CHANGE MASTER TO命令中配置。
补充说明:
Exec_Master_Log_Pos:在多线程从库上,Exec_Master_Log_Pos包含任何未提交事务之前最后一个点的位置。这不一定与中继日志中最新的日志位置相同,因为多线程从库可能以与二进制日志中不同的顺序在不同数据库上执行事务。Seconds_Behind_Master:该列提供 SQL 线程执行的中继日志中最新事件的时间戳(主库上的时间 )与从库机器实际时间的秒数差。这种延迟通常发生在主库并行处理大量事件,而从库必须串行处理时,或者从库硬件在高流量期间无法处理主库能处理的事件量时。如果从库未连接到主库,该列为NULL。大型事务或长时间执行的操作(如更新无主键的大表 )可能导致该值增加。 注意:该列不显示 I/O 线程的延迟或主库事件网络传输的延迟。
复制从库 I/O 线程状态(Replication Slave I/O Thread States)
在 SHOW PROCESSLIST 输出的 State 列中,最常见的 I/O 线程状态如下:
-
Connecting to master
- 线程正在尝试连接到主库。
-
Waiting for master to send event
- 从库已连接,正在等待二进制日志事件。
- 如果主库空闲,该状态可能会持续很长时间。
- 在
slave_read_timeout秒后超时,并尝试重新连接。
-
Queuing master event to the relay log
- 线程已读取一个事件,正在将其复制到中继日志,以便由 SQL 线程处理。
-
Waiting to reconnect after a failed binlog dump request(因二进制日志转储请求失败,等待重新连接 )
- 二进制日志转储请求因断开连接而失败。
- 线程进入此状态,期间会休眠并定期尝试重新连接。
- 可通过
CHANGE MASTER TO的MASTER_CONNECT_RETRY选项指定重试间隔。
-
Reconnecting after a failed binlog dump request(二进制日志转储请求失败后,正在重新连接 )
- 线程正在尝试重新连接到主库。
-
Waiting to reconnect after a failed master event read(因读取主库事件失败,等待重新连接 )
- 读取过程中发生断开连接。线程会休眠指定秒数后,尝试重新连接。
- 默认是 60 秒。
- 可通过
CHANGE MASTER TO的MASTER_CONNECT_RETRY选项指定秒数。
-
Reconnecting after a failed master event read(因读取主库事件失败,正在重新连接 )
- 线程正在尝试重新连接到主库。
- 线程重新连接后,状态会变为
Waiting for master to send event(等待主库发送事件 )。
-
Waiting for the slave SQL thread to free enough relay log space(等待从库 SQL 线程释放足够的中继日志空间 )
- 中继日志的总大小超过了
relay_log_space_limit的值(仅当该值非零时生效;值为 0 表示中继日志大小无限制 )。 - I/O 线程会等待,直到 SQL 线程通过处理中继日志内容并删除,释放出足够空间。
- 中继日志的总大小超过了
复制从库 SQL 线程状态
最常见的 SQL 线程状态如下:
-
等待中继日志中的下一个事件
- 是 “从中继日志读取事件” 之前的初始状态。
-
从中继日志读取事件
- 线程已从中继日志中读取一个可处理的事件。
-
创建临时文件(追加)
- 在重放
LOAD DATA INFILE语句前的状态。 - 线程正在执行
LOAD DATA语句,会将数据追加到一个临时文件中,从库后续会从该文件读取行数据。
- 在重放
-
从库已读取所有中继日志;等待更多更新
- 线程已处理完中继日志文件中的所有事件。当前正在等待 I/O 线程向中继日志写入新事件。
-
等待至主库执行事件后的 … 秒
- SQL 线程已读取一个事件,但在等待从库延迟(配置的延迟时间 )结束。
- 可通过
CHANGE MASTER TO语句的MASTER_DELAY选项设置延迟。
-
等待协调器分配事件
- 仅出现在多线程从库的工作线程中。
- 一个工作线程正在等待协调 SQL 线程将任务分配到工作队列。
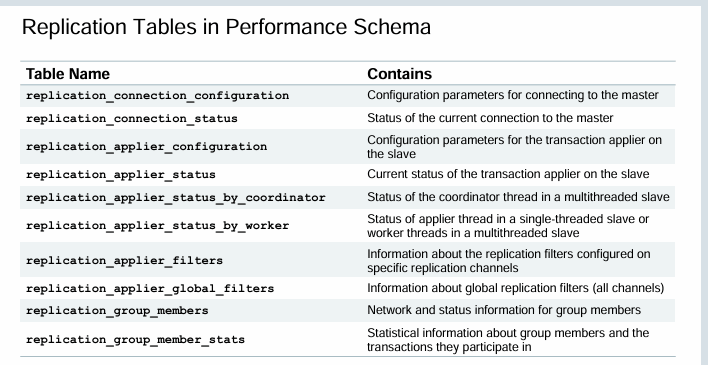
使用性能模式监控复制(Monitoring Replication by Using Performance Schema)
性能模式(Performance Schema)包含 replication_* 表,这些表在 SHOW SLAVE STATUS 提供的信息基础上进行了增强,使你能够:
- 对想要显示的信息进行更精细的控制
- 获取更完善的诊断信息
SHOW SLAVE STATUS仅报告最新的协调器线程和工作线程错误。- 可获取每个工作线程处理的最后一个事务的详细信息。
- 将诊断信息持久化到表或视图中
- 以编程方式访问复制指标
复制故障排查Troubleshooting replication
MySQL 复制故障排查(Troubleshooting MySQL Replication)
- 查看错误日志
- 错误日志可提供足够信息,帮助你识别并修正复制中的问题。
- 在主库执行
SHOW MASTER STATUS语句- 若
Position值非零,说明主库已启用日志记录。
- 若
- 验证主库和从库是否均有唯一的非零服务器 ID(
server_id)- 主库和从库的
server_id必须不同。
- 主库和从库的
- 在从库执行
SHOW SLAVE STATUS命令,或查询性能模式(Performance Schema)中的复制表- 当从库正常工作时,
Slave_IO_Running和Slave_SQL_Running会显示Yes。 Last_IO_Error和Last_SQL_Error会显示 I/O 线程和 SQL 线程最近的错误消息。
- 当从库正常工作时,
注意:如果你无法使用主库上的有效账号登录从库,可能是因为你在主库上通过 CREATE USER 或 GRANT 创建了用户账号,该账号通过 mysql.user 表复制到从库,但复制过程未刷新权限。可在从库上,通过其他账号使用 mysqladmin flush-privileges 命令,或执行 FLUSH PRIVILEGES 来解决。
- 在主库和从库执行
SHOW PROCESSLIST命令- 检查 Binlog dump 线程、I/O 线程和 SQL 线程的状态。
- 对于突然停止工作的从库,检查最近复制的语句
- 若因约束问题或其他错误导致操作失败,SQL 线程会停止。
- 错误日志会包含导致 SQL 线程停止的事件。
- 查阅已知的复制限制。
- 参考:http://dev.mysql.com/doc/mysql/en/replication-features.html
- 验证从库数据未被直接修改(即未通过复制以外的方式修改 )。
- 若因约束问题或其他错误导致操作失败,SQL 线程会停止。
检查错误日志
检查错误日志(Examining the Error Log)
-
错误日志存储了复制开始的相关信息,以及复制过程中发生的任何错误信息。
-
始终优先检查错误日志。
-
以下示例显示了复制成功启动,但在复制从库上已存在的用户时随后失败:
1 2 3 4 5 6 7 8 9 10 11 12date-and-time 95 [System] [MY-010562] [Repl] Slave I/O thread for channel '': connected to master 'repl@10.0.0.23:3306', replication started in log 'binlog.000005' at position 1384 date-and-time 96 [ERROR] [MY-010594] [Repl] Slave SQL for channel '': Error 'Operation CREATE USER failed for user 'caching_sha2_password' as ...' Error: 'CREATE USER 'user'@'%' IDENTIFIED WITH 'caching_sha2_password' AS 'database': ' . Query: MY-001396 date-and-time 96 [Warning] [MY-010584] [Repl] Slaves: Operation CREATE USER failed for 'user'@'%' (Error code: MY-001396) date-and-time 96 [ERROR] [MY-010586] [Repl] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'binlog.000006' position 235 -
以下序列显示了从库 I/O 线程读取主库二进制日志时失败的情况:
1 2 3 4 5 6 7 8 9 10 11 12 13date-and-time 1421 [System] [MY-010562] [Repl] Slave I/O thread for channel '': connected to master 'repl@10.0.0.23:3306', replication started in log 'binlog.000007' at position 200 date-and-time 1421 [ERROR] [MY-010557] [Repl] Error reading packet from server for channel '': bogus data in log event; the first event 'binlog.000007' at 200, the last event read from './binlog.000007' at 124, the last byte read from './binlog.000007' at 219. (server_errno=1236) date-and-time 1421 [ERROR] [MY-013114] [Repl] Slave I/O for channel '': Got fatal error 1236 from master when reading data from binary log: 'bogus data in log event; the first event 'binlog.000007' at 200, the last event read from './binlog.000007' at 124, the last byte read from './binlog.000007' at 219.', Error_code: MY-013114
SHOW SLAVE STATUS 错误详情
- Last_IO_Error(最后 I/O 线程错误)、Last_SQL_Error(最后 SQL 线程错误):
- 分别是导致 I/O 线程或 SQL 线程停止的最近一次错误的错误消息。
- 在正常复制期间,这些字段为空。
- 如果发生错误并导致这些字段中出现消息,该错误消息也会出现在错误日志中。
- Last_IO_Errno(最后 I/O 线程错误号)、Last_SQL_Errno(最后 SQL 线程错误号):
- 分别是与导致 I/O 线程或 SQL 线程停止的最近一次错误相关联的错误编号。
- 在正常复制期间,这些字段包含数字 0 。
- Last_IO_Error_Timestamp(最后 I/O 线程错误时间戳)、Last_SQL_Error_Timestamp(最后 SQL 线程错误时间戳):
- 分别是导致 I/O 线程或 SQL 线程停止的最近一次错误的时间戳。
- 在正常复制期间,这些字段为空
检查 I/O 线程状态
如果从服务器(slave)正在运行,执行 SHOW PROCESSLIST 来检查连接到主服务器(master)的 I/O 线程状态:
- 验证在主服务器上用于复制的用户的权限
- 验证主服务器的主机名和端口是否正确
- 验证在主服务器或从服务器上网络功能未被禁用(通过
--skip-networking选项 ) - 尝试对主服务器执行 ping 操作,以验证从服务器能够连接到主服务器
监控多源复制
- 执行
SHOW SLAVE STATUS FOR CHANNEL <channel name>(显示指定通道的从库状态 )。 - 或者,查询性能模式(Performance Schema)的
replication_*表,指定通道名称。- 说明:
CHANNEL_NAME字段存在于每个性能模式复制表中。
- 说明:
|
|
上述示例演示了查询性能模式的 replication_connection_status 表,以监控在复制通道 master1 上,处理从服务器(slave server )到主服务器(master server )连接的 I/O 线程的状态。