目标:
- 描述 MySQL InnoDB 集群和组复制
- 例举典型用例
- 对比两种不同的部署模式
- 配置 MySQL InnoDB 集群
- 管理 MySQL InnoDB 集群
概述及架构
什么是 MySQL InnoDB 集群
- 为 MySQL 提供完整且可扩展的高可用性解决方案
- 易于配置和管理集群中的一组服务器实例
- 使用 MySQL Group Replication(MySQL 组复制 )在组内所有服务器之间复制数据
- AdminAPI 让您无需直接操作组复制。
- 您可通过 MySQL Shell(使用您选择的 Python 或 JavaScript 编程语言 )使用 AdminAPI。
- 自动管理故障转移
- 如果组中的某台服务器出现故障,集群会自行重新配置。
- 该组至少需要三台服务器才能实现容错
- 使客户端能够透明地连接到该组
- 客户端通过 MySQL Router 连接到该组,无需了解组内各个实例的详细信息。
要使用 MySQL InnoDB Cluster,您必须下载并安装 MySQL Shell 和 MySQL Router 软件。
架构
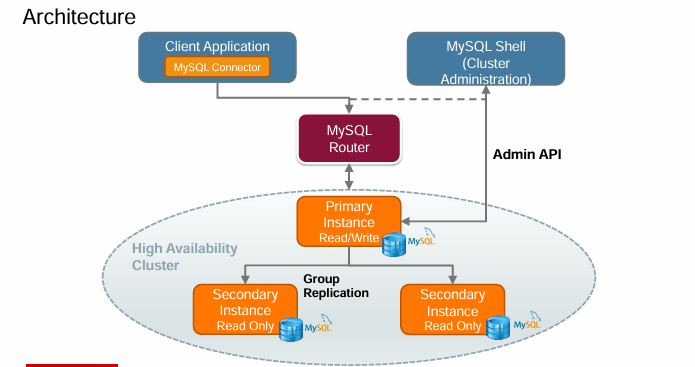
集群依赖于 MySQL 组复制(MySQL Group Replication),该功能安装在集群中的每个服务器实例上。组复制是一个 MySQL 服务器插件,使你能够创建灵活的复制拓扑,若集群中的某台服务器离线,这些拓扑可自动重新配置。要形成一个具备高可用性的组,必须至少有三台服务器。组可以在单主模式(同一时间只有一台服务器接受更新)或多主模式(所有服务器都可接受更新,即便更新是并发发出的 )下运行。
MySQL 组复制插件在 5.7 版本中引入,但直接使用起来较为复杂。MySQL InnoDB Cluster 引入了新的组件,这些组件紧密集成,让组复制的设置和管理变得更加容易。其中包括 MySQL Router,它位于应用程序和集群之间,将流量路由到合适的集群实例。如果主实例出现故障,集群会自动将另一个实例提升为主实例,MySQL Router 会开始将流量路由到新的主实例。所有这些操作都无需数据库管理员(DBA)干预。
你可以使用 MySQL Shell 来管理集群。MySQL Shell 是一个新的交互式界面,使你能够通过新的管理 API(Admin API),使用熟悉的 JavaScript 或 Python 语法来管理 MySQL。
MySQL 组复制插件(MySQL Group Replication Plugin)
组复制是 MySQL 的一个插件,它使一组服务器能够在彼此之间复制数据,并具备以下功能:
- 自动处理服务器故障转移
- 当成员因崩溃、故障或重新连接而加入或离开组时,自动重新配置组
- 容错能力
- 冲突解决
- 一个高可用、已复制的数据库
组复制的工作原理
- 服务器属于一个复制组。
- 一个复制组最多可包含 9 台服务器。
- 至少需要 3 台服务器才能实现容错。
- 组复制使用全局事务标识符(GTIDs)。
- 该组由一个 UUID 定义。
- 组成员身份自动管理。
- 加入或重新加入组的服务器会自动与其他服务器同步。
- 服务器可随时离开和加入组。
- 复制组以以下两种模式之一运行:
- 单主模式:组中仅有一台服务器接受更新。
- 多主模式:组中的所有服务器都接受更新。
- 更改会复制到组的所有成员。
成员服务器被配置为属于一个复制组。根据组复制模式的不同,客户端向一个或多个成员写入数据。更改会复制到复制组的所有成员。
组可以在单主模式下运行,具备自动主选举功能,此时仅有一个成员接受更新。或者,组也可以部署在多主模式下,在此模式中,所有成员都接受更新,即便这些更新是并发发出的。
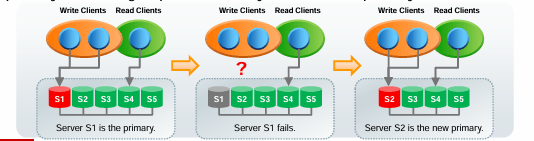
单主模式
- 一个组成员接受写操作(主节点)。
- 其余组成员作为只读的热备(从节点)。
- 这是默认模式,在大多数场景中效果最佳。
- 应用程序和开发人员仅与单个服务器交互以进行更新。
- 这避免了多主模式的一些限制。
- 应用程序可以连接到任何从节点以读取数据。
- 如果主节点发生故障,组会自动选举一个新的主节点:(下方图示说明:最初服务器 S1 是主节点,写客户端与 S1 交互、读客户端可连接 S1 - S5 ;当 S1 故障后,组自动选举,最终 S2 成为新主节点,写客户端转而与 S2 交互)
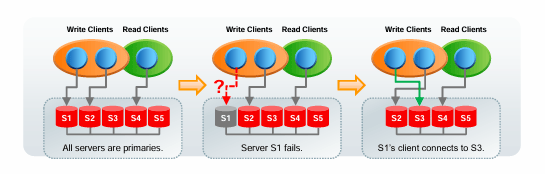
多主模式
- 所有服务器都可接收更新,即便更新是并发执行的。
- 然而,它并不能扩展写操作,因为所有服务器仍需写入所有更新。
- 如果某台服务器发生故障,客户端可连接到复制组中的任何其他服务器。
- 与单主模式相比,存在更多限制
(下方图示说明:初始所有服务器(S1 - S5 )都是主节点,写客户端可连任意节点;当 S1 故障后,S1 的客户端可连接到 S3 )
冲突解决
- 组中的每个服务器独立执行事务,但所有服务器必须就决策达成一致。
- 读写事务在被组接收时进行提交。
- 为了应用事务,大多数成员必须同意(“认证”)该事务在全局事务序列中的顺序。
- 只读事务不需要组批准,会立即提交。
- 读写事务在被组接收时进行提交。
- 如果两个并发事务影响同一行,就会发生冲突。
- 首先提交的事务 “获胜”。其他事务回滚。
- 如果网络分区导致出现 “脑裂” 情况(组内成员无法达成一致),则系统无法达成共识,需要人工干预。
共识与法定人数(Consensus and Quorum)
- 每当发生需要复制的更改时(如常规事务和组成员身份变更 ),组需要达成共识。
- 共识或法定人数要求组内过半数(超过一半 )成员就某一决策达成一致。
- 当发生多次非自愿故障,导致多数服务器突然从组中移除时,可能会失去法定人数。
- 剩余服务器无法判断其他服务器是崩溃了,还是网络分区使它们被隔离。
- 剩余服务器无法自动重新配置。需要人工干预。
- 任何自愿退出组的服务器,可通知组内其他成员进行自我重新配置。因此,法定人数可得以维持。
示例:在一个由 5 台服务器组成的组中,如果其中 3 台突然无响应,多数派就无法形成,因此无法达成法定人数。实际上,剩下的 2 台无法判断另外 3 台是崩溃了,还是网络分区使这 2 台被单独隔离,因此组无法自动重新配置。参考标题为《恢复法定人数丢失(Restoring Quorum Loss)》的幻灯片,了解恢复集群法定人数的流程。
不过,在上述 5 台服务器中有 3 台同时离开的场景中,如果这 3 台离开的服务器逐一告知组它们要离开,那么成员身份就能从 5 台调整为 2 台,同时在调整过程中保障法定人数。
使用场景
- 弹性复制(Elastic replication):
- 涉及复制基础架构的服务器数量非常灵活多变的环境。
- 高可用分片(Highly available shards):
- 分片是一种实现写操作横向扩展的流行方法。
- 每个分片可映射到一个复制组。
- 作为标准主 - 从复制的替代方案(As an alternative to standard master - slave replication):
- 使用单主模式时,以下操作是自动进行的:
- 主 / 从角色的分配
- 当前主节点发生故障时,新主节点的选举
- 在主节点和从节点上设置读 / 写模式
- 关于哪个服务器是主节点的全局一致视图
- 使用单主模式时,以下操作是自动进行的:
组复制:要求和限制
- 必需条件(Required)
- 通信方面:
- 参与复制的服务器需处于相近网络位置(低延迟网络环境 ),以降低延迟。
- 冲突检测方面:
- 使用 InnoDB 存储引擎。
- 每张表必须有主键。
- 启用 GTIDs(全局事务标识符 )。
- 复制方面:
- 启用二进制日志记录及从库更新功能。
- 二进制日志格式为 ROW 格式。
- 元数据必须以 TABLE 格式存储。
- 设置
transaction_write_set_extraction = XXHASH64。
- 通信方面:
- 禁止情况(Forbidden)
- 常规情况:
- 二进制日志事件校验和。
- 表锁和命名锁。
- 复制过滤器。
- 多主模式下:
- 可串行化(SERIALIZABLE )隔离级别。
- 级联外键。
- 在不同成员上对同一对象执行并发的数据定义语言(DDL )和数据操作语言(DML )语句 。
- 常规情况:
必须确保 transaction_write_set_extraction 变量设置为 XXHASH64,这样在收集行记录写入二进制日志时,服务器也会收集写集合。基于主键的写集合能简化操作,并且提供一个唯一标识被修改行的标签。组复制利用该标签检测冲突。
在多主模式下,不能在不同成员上对同一对象执行数据定义语言(DDL )和数据操作语言(DML )语句,因为这可能导致无法检测的冲突。
工具
MySQL Shell(mysqlsh)
- 是一款面向 MySQL 的高级客户端和代码编辑器。
- 支持使用 JavaScript、Python 或 SQL 命令进行脚本编写
- 你可以交互输入命令,也可以批量执行命令。
- 可通过分别输入
\js、\py或\sql,在语言之间切换。
- 能够通过 API 访问 MySQL 功能
- XDevAPI:与运行 X 插件的 MySQL 服务器通信,以处理关系型数据和 MySQL 文档存储。
- AdminAPI:配置和管理 MySQL InnoDB 集群。
- 支持以制表符分隔、表格和 JSON(JavaScript 对象表示法 )格式输出。
- 通过全局
Session(会话 )对象与 MySQL 服务器交互- 若使用 Python 脚本,可通过调用
mysqlx模块的getSession()方法创建Session对象。 - 若使用 SQL,客户端连接时会创建
Session对象。
- 若使用 Python 脚本,可通过调用
使用 MySQL Shell 执行脚本(Using MySQL Shell to Execute a Script)
示例:
-
从文件加载 JavaScript 代码进行批处理:
1$ mysqlsh --file script.js -
将 JavaScript 文件重定向到标准输入以执行:
1$ mysqlsh < script.js -
将 SQL 重定向到标准输入以执行:
1$ echo "show databases;" | mysqlsh --sql --uri root@127.0.0.1:3306 -
使批处理文件可执行(仅适用于 Linux):
1 2#!/usr/local/mysql-shell/bin/mysqlsh --file print("Hello World\n");
MySQL 路由器(mysqlrouter)
-
作为中间件,在客户端应用与后端 MySQL 服务器之间提供透明路由功能
-
通过自动路由连接来管理故障转移
- 无需自定义代码;采用负载均衡策略
-
提供负载均衡功能
- 将数据库连接分布到服务器池中,以实现性能优化和可扩展性
-
实现了可插拔架构
- 开发者可扩展产品,并为自定义用例创建插件
配置集群
部署场景(Deployment Scenarios)
你可以使用以下两种方法之一配置 MySQL InnoDB 集群:
- 沙盒部署(Sandbox deployment):允许你在生产服务器部署之前,在本地测试 MySQL InnoDB 集群。
- 生产部署(Production deployment):允许你在网络中的多台主机上,部署构成集群的各个实例
部署沙盒实例并创建集群
-
在 3310、3320 和 3330 端口部署三个沙盒实例:
1 2 3mysql-js> dba.deploySandboxInstance(3310) mysql-js> dba.deploySandboxInstance(3320) mysql-js> dba.deploySandboxInstance(3330) -
连接到种子实例(数据所在的实例 )并创建集群:
1 2mysql-js> \connect root@localhost:3310 mysql-js> var cluster = dba.createCluster('mycluster') -
添加实例:
1 2mysql-js> cluster.addInstance(3320) mysql-js> cluster.addInstance(3330)
补充说明:
dba shell 全局变量代表 AdminAPI。你可以调用其 deploySandboxInstance 方法,传入实例所需的 TCP 端口作为参数。
然后,你可以使用 shell 的 \connect 方法(或其简写形式,如示例中的 \connect user@localhost:port )连接到实例。本示例使用 URI 字符串指定连接详情,但你也可以使用字典。
当你使用 dba.createCluster() 创建集群时,该操作会返回一个 cluster 对象,你可以将其赋值给变量。你可以使用此对象操作集群,例如添加实例或检查集群状态。如果你希望日后重新获取集群,例如在重启 MySQL Shell 后,可使用 dba.getCluster(clustername, options)。将 connectToPrimary 选项设置为 false 以查询并连接到主实例。例如:
|
|
MySQL InnoDB 集群依赖 SET PERSIST 来持久化实例配置设置。只有在运行 MySQL 8.0 或更高版本,且 persisted_globals_load=ON(默认设置 )时,自动持久化才可用。在支持自动持久化的本地实例上,配置设置会存储在实例的 mysqld-auto.cnf 文件中。如果本地实例不支持自动持久化,AdminAPI 会尝试将这些更改写入实例的选项文件。
分布式恢复(Distributed Recovery)
- 是用于同步加入或重新加入集群的成员节点数据的过程。
- 选择集群中一个已存在的成员节点作为 “捐赠者(donor)”,以更新待加入的成员节点。
- 有两种可用方式:
- 克隆恢复(Clone recovery)
- 使用克隆插件(clone plugin)对捐赠者节点的数据进行快照,并将快照恢复到待加入的成员节点。
- 会删除待加入成员节点中所有已存在的数据。
- MySQL 8.0.17 及以上版本可用。
- 增量恢复(Incremental recovery)
- 复制捐赠者节点的二进制日志,并在待加入的成员节点上应用这些事务。
- 如果所有集群成员节点中所需的二进制日志已被清理(purge),则恢复会失败。
- 克隆恢复(Clone recovery)
补充说明:
默认情况下,集群会自动选择最合适的恢复方式,但你也可以选择配置此行为。你可以在 cluster.addInstance() 方法中使用 recoveryMethod 选项来指定恢复方式,有效值为 'clone' 和 'incremental'。
从 8.0.17 版本开始,若在一个已安装 MySQL 克隆插件(MySQL Clone plugin)的实例上,使用 dba.createCluster() 创建新集群,克隆插件会被自动安装,且集群会配置为支持克隆恢复。InnoDB 集群恢复账号会被创建,并赋予所需的 BACKUP_ADMIN 权限,以支持克隆功能
将客户端连接到集群(Connecting Clients to the Cluster)
-
在与应用程序相同的主机上安装 MySQL Router。
-
使用种子实例(seed instance)上的元数据服务器引导(bootstrap)MySQL Router:
1$ mysqlrouter --bootstrap user@hostname:port --directory=directory_path -
启动 MySQL Router:
1$ directory_path/start.sh- 这会创建读 / 写(read/write)和只读(read-only)TCP 端口。
-
将客户端连接到合适的 TCP 端口。
- 例如,使用 MySQL Shell 以 root 用户连接到读 / 写端口 6446:
1$ ./bin/mysqlsh --uri root@localhost:6446 -
要验证你连接到的机器,可查询
port和hostname服务器变量。
补充说明:
--directory 选项配置 MySQL Router 从一个独立的目录运行。这使你能够在同一主机上部署多个 Router 实例,且无需 root 权限。
管理集群
管理沙盒实例(Managing Sandbox Instances)
使用以下函数管理沙盒实例:
dba.deploySandboxInstance(port):创建一个新实例。dba.startSandboxInstance(port):启动一个沙盒实例。dba.stopSandboxInstance(port):优雅地停止一个正在运行的实例,与dba.killSandboxInstance()不同。dba.killSandboxInstance(port):立即停止一个正在运行的实例。适用于模拟意外停机场景。dba.deleteSandboxInstance(port):从文件系统中移除一个沙盒实例。
注意
这些函数中的每一个都接受一个可选的 options(选项)对象作为第二个参数,该对象会影响操作结果
检查集群状态(Checking the Status of a Cluster)
|
|
注意
连接集群的方式会影响 cluster.status() 的输出。如果通过只读连接访问集群,你将只能看到与从实例(secondary instances)相关的状态信息。若要查看主实例(primary instance (s))的状态信息,请使用读 / 写连接。
查看集群的结构(Viewing the Structure of a Cluster)
|
|
检查实例的状态(Checking the State of an Instance)
- 执行
cluster.checkInstanceState(instance)以验证实例的 GTID 状态与集群的关联情况。- 分析实例已执行的 GTID 与集群上已执行 / 清理的 GTID,判断该实例是否可加入集群。
- 此方法的输出结果为以下之一:
OK new:实例未执行任何 GTID 事务;因此,它不会与集群已执行的 GTID 冲突。OK recoverable:实例已执行 GTID,但这些 GTID 与集群种子实例已执行的 GTID 无冲突。ERROR diverged:实例已执行的 GTID 与集群种子实例已执行的 GTID 存在分歧(冲突 )。ERROR lost_transactions:实例已执行的 GTID 数量多于集群种子实例已执行的 GTID 数量。
从集群中移除实例(Removing Instances from the Cluster)
通过调用 cluster.removeInstance() 方法从集群中移除实例,用法如下:
|
|
将实例重新加入集群(Rejoining an Instance to the Cluster)
- 重启后的实例默认会尝试自动重新加入集群。
- 与集群其他成员失去连接超过 5 秒的实例会成为 “疑似成员”,并在驱逐超时(由
expelTimeout选项控制 )后被驱逐。 - 被驱逐的实例可配置为尝试自动重新加入集群:
- 若自动重新加入失败,会等待 5 分钟后重试。
- 在配置的自动重新加入最大重试次数(
autoRejoinTries选项 )失败后,实例会切换到配置的退出动作状态(exitStateAction选项 )。
- 若已离开集群的实例(例如,因连接丢失 )未自动重新加入或自动重新加入失败,执行
cluster.rejoinInstance(instance)手动重新加入。
恢复法定人数丢失(Restoring Quorum Loss)
若某个实例发生故障,集群可能会丢失法定人数(quorum),即无法选举新主库的能力。可使用 cluster.forceQuorumUsingPartitionOf() 重新建立法定人数。
|
|
从严重故障中恢复集群(Recovering the Cluster from a Major Outage)
若集群完全停滞(故障停运),执行以下步骤:
-
重启集群实例。
-
例如,在沙盒部署环境中:
1 2 3mysql-js> dba.startSandboxInstance(3310) mysql-js> dba.startSandboxInstance(3320) mysql-js> dba.startSandboxInstance(3330)
-
-
连接到一个实例并启动 MySQL Shell。
-
在 MySQL Shell 中,连接到集群并执行
1dba.rebootClusterFromCompleteOutage():
1 2mysql-js> \connect 'root@localhost:3310' mysql-js> var cluster = dba.rebootClusterFromCompleteOutage()
补充说明:
dba.rebootClusterFromCompleteOutage() 函数用于从完全故障中重启集群。它会将 MySQL Shell 所连接的实例选为新的种子实例(seed instance)并恢复集群。种子实例应包含最新的数据。此外,它还会根据用户提供的选项更新集群配置。
若此过程失败(说明集群元数据已严重损坏 ),你可能需要删除元数据并重新从头创建集群。可使用 dba.dropMetadataSchema() 删除集群元数据。
解散集群(Dissolving a Cluster)
要完全解散集群,请执行以下步骤:
- 连接到一个可读写(read/write)实例。
- 执行
cluster.dissolve()。- 移除所有集群元数据和配置,并禁用组复制(group replication)。
- 实例之间曾复制的数据会保留完整。
- 清空所有已赋值给
Cluster对象的变量。
|
|
禁用 super_read_only
每当组复制(Group Replication)停止时,super_read_only 变量会被设置为 ON,以确保不会对实例进行写入操作。当你尝试对这样的实例使用以下 AdminAPI 命令时,系统会让你选择是否在该实例上设置 super_read_only=OFF:
dba.configureInstance()dba.configureLocalInstance()dba.createCluster()dba.rebootClusterFromCompleteOutage()dba.dropMetadataSchema()
在非交互执行中,你还可以通过将 clearReadOnly 选项设置为 true 来实现(关闭 super_read_only )。例如:
|
|
交互会话示例:
|
|
自定义 MySQL InnoDB 集群(Customizing a MySQL InnoDB Cluster)
执行 dba.createCluster(String name, Dictionary options) 创建 InnoDB 集群时,你可以提供一系列选项来自定义集群。options 参数需指定为 JSON 对象。可配置的部分取值如下:
-
multiPrimary:布尔值,用于定义一个包含多个可写实例的 InnoDB 集群,默认值为false(即单主模式 )。 -
failoverConsistency:字符串值,指示集群提供的一致性保障,默认值为
1EVENTUAL。
- 若设为
BEFORE_ON_PRIMARY_FAILOVER,新主库会在应用完旧主库的积压事务前,暂停新查询的执行。
- 若设为
-
expelTimeout:整数值,定义集群成员在驱逐无响应成员前应等待的时间(秒 ),默认值为0。
其他可用选项包括:
interactivedisableClonegtidSetIsCompleteadoptFromGRmemberSslModeipWhitelistgroupNamelocalAddressgroupSeedsexitStateActionmemberWeightautoRejoinTries
groupName、localAddress 和 groupSeeds 属于高级选项,不建议使用,因为手动配置这些值可能导致组复制(Group Replication )错误。建议让 AdminAPI 自动配置它们。
这些选项中的一部分可通过 cluster.setOption() 函数进行修改。
自定义实例(Customizing an Instance)
使用 dba.addInstance(InstanceDef instance, Dictionary options) 将实例添加到集群时,你可以提供一系列选项来自定义该实例。可配置的部分取值如下:
recoveryMethod:首选的状态恢复方法,默认值为AUTO。- 可设置为
clone(克隆恢复 )或incremental(增量恢复 )。
- 可设置为
exitStateAction:实例意外离开集群时的状态,默认值为READ_ONLY。- 可设置为
ABORT_SERVER(实例关闭 )或OFFLINE_MODE(只读,且仅接受具有管理权限的客户端连接 )。
- 可设置为
memberWeight:用于自动故障转移时主库选举的整数值(百分比权重 ),默认值为50。autoRejoinTries:配置实例被驱逐后尝试重新加入集群的次数,默认值为0。
其他可用选项包括:
labelwaitRecoverypasswordmemberSslModeipWhitelistlocalAddressgroupSeeds
这些选项中的一部分可通过 cluster.setInstanceOption() 函数进行修改
在集群中配置安全连接(Configuring Secure Connection in a Cluster)
- 使用
dba.createCluster()搭建集群时,memberSslMode选项用于配置 SSL 连接。其模式如下:- AUTO(默认 ):若服务器实例支持 SSL,则自动启用;若不支持,则禁用。
- DISABLED:为种子实例禁用 SSL 加密。
- REQUIRED:为集群中的种子实例启用 SSL 加密。若无法启用,会抛出错误。
- 执行
cluster.addInstance()和cluster.rejoinInstance()命令时,memberSslMode选项用于配置 SSL 连接。其模式如下:- AUTO(默认 ):根据集群配置,自动启用或禁用 SSL 加密。
- DISABLED:为该实例禁用 SSL 加密。
- REQUIRED:为集群中的该实例启用 SSL 加密。
对于沙盒实例,cluster.deploySandboxInstance() 会在可能的情况下,默认尝试部署启用 SSL 加密的实例。
创建服务器白名单(Creating a Server Whitelist)
- 集群会维护一份属于该集群的已授权服务器列表,称为白名单。
- 只有白名单中的服务器才能加入集群。
- 默认白名单包含服务器网络接口上的私有网络地址。
- 使用
ipWhitelist选项,通过dba.createCluster()、cluster.addInstance()或cluster.rejoinInstance()创建自定义白名单,以增强安全性。- 以逗号分隔的列表形式传入 IP 地址或子网的 CIDR 表示法,并用引号包裹。
- 在实例上配置
group_replication_ip_whitelist系统变量。
CIDR 表示法示例:
10.0.0.0/8包含的 IP 地址范围是10.0.0.0–10.255.255.255172.16.0.0/16包含的 IP 地址范围是172.16.0.0–172.16.255.255172.16.0.0/24包含的 IP 地址范围是172.16.0.0–172.16.0.255192.168.0.0/24包含的 IP 地址范围是192.168.0.0–192.168.0.255